
- View more
Meilleures façons de convertir mov en mp4
Les fichiers MOV sont couramment utilisés pour stocker des vidéos et des films, mais ils ne sont pas aussi compatibles que les fichiers MP4. Si vous avez des fichiers MOV ... - View moreDans le monde numérique actuel, la sécurité informatique est un ...
- View moreDans un monde où les smartphones sont devenus une partie ...



BUREAUTIQUE
-
Convertisseur de millilitres en centilitres
Le centilitre comme le millilitre est une unité de mesure servant dans plusieurs domaines et même en cuisine. Mais, pour d'autres personnes, convertir le millilitre en centilitre peut être un ... -
Comment activer Word gratuitement ?
Microsoft Office est utilisé dans le monde entier à toutes fins telles que la création de CV, de présentation, de portefeuille, de problèmes mathématiques dans Excel, etc. Mais certaines personnes ... -
Vidéoprojecteur cassé : comment changer la lampe ?
Par inadvertance, vous avez fait tomber votre vidéoprojecteur. Au moment d'en faire usage, vous vous rendez compte que l'image est floue et de piètre qualité. Après une inspection de l'appareil, ...



- Les fichiers MOV sont couramment utilisés pour stocker des vidéos et des films, mais ils ne sont pas aussi compatibles que les fichiers MP4. Si vous avez des fichiers MOV que vous souhaitez lire sur différents appareils, il est préférable de les convertir en MP4. Si vous avez besoin de ...
- Les horaires d'ouverture du service client Orange sont un élément important à prendre en compte pour les clients qui souhaitent les contacter. Cependant, il peut arriver que les clients aient besoin de contacter le service client Orange en dehors des heures d'ouverture du service client. Dans cet article, nous allons ...
- Les appareils Android ou iPhone mettent à votre disposition une application de messagerie électronique. Grâce à ces applications, vous pouvez accéder à vos différents comptes emails. Pour cela, vous devez configurer les mails sur votre téléphone. Cette procédure varie d’un appareil à un autre. Plus d’explications dans la suite de ...
- Dans le monde technologique actuel, où la performance et l'esthétique sont étroitement liées, un appareil qui combine les deux est une trouvaille précieuse. Le PC tout-en-un Dell de 27 pouces est un tel trésor. Avec son design élégant, son écran de haute qualité et sa puissance de traitement impressionnante, cet ...
- Nous l'avons tous fait, nous avons immédiatement essayé de prendre le ciel avec un nouveau drone, qui s'est rapidement écrasé. Il est facile de se tromper en pilotant votre nouveau quadricoptère, voici donc quelques-unes des erreurs les plus courantes et ce que nous vous recommandons de faire pour les éviter. ...
- Dans l'univers numérique actuel, la messagerie instantanée s'est imposée comme un outil de communication essentiel. Messenger, une application phare de Facebook, est devenue incontournable pour rester en contact avec la famille, les amis ou les collègues. Toutefois, certaines personnes souhaitent utiliser Messenger sans nécessairement conserver un compte Facebook actif, pour ...





INFORMATIQUE
-
Comprendre le fonctionnement de Telegram Web
Telegram fait le pont entre WhatsApp et signal. Outre sa fonction primaire qui permet d’envoyer différent type de messages, cette application offrent plusieurs autres avantages. La plupart des fonctionnalités sont ... -
Formats de fichiers vidéo : comprendre les extensions courantes
Naviguer dans l'univers des formats de fichiers vidéo peut souvent ressembler à décrypter un code complexe. Pour les non-initiés, les diverses extensions telles que AVI, MP4, MOV ou MKV ne ...






MARKETING

Qu'est-ce qu'une offre de services ?
Si vous recherchez ce qu'est une offre de service , il vous suffit de consulter nos liens ci-dessous : 1. Services et offres de services — ServiceNow https://www.servicenow.com/content/dam/servicenow-assets/public/en-us/doc-type/success/quick-answer/services-service-offerings.pdf 2. Qu'est-ce que ...




NEWS




SÉCURITÉ
Charger plus
WEB
Comment faire un copier-coller du texte extrait d'une image ?
Imaginez qu'il existe un moyen simple d'extraire le texte d'une image, d'un document numérisé ou d'un fichier PDF et de le coller rapidement dans un ...Comment télécharger des films avec Torrentz2 ?
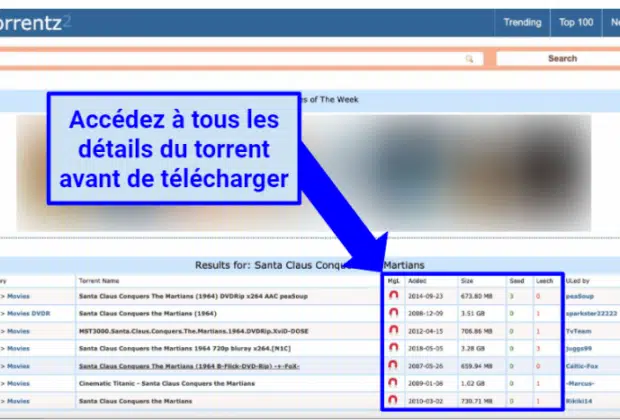
Si vous êtes amateur de cinéma, de jeux et de logiciels, vous avez sûrement entendu parler de torrent. En effet, c’est l’une des plus grandes ...Torrentz2 : comment accéder à ce site ?
Les internautes sont des champignons dans le téléchargement des fichiers illégaux. Plusieurs Torrents Content leur permettent de s’en sortir facilement. Mais le problème majeur est ...WebRip : fonctionnement de ce format vidéo
De nos jours, il n’est pas rare de trouver des archives composées d’une large variété de vidéos sous le format WebRip. Il y a différentes ...


Charger plus